MySQL has always been among one of the top few database management systems used worldwide according to one of the leading ranking websites, Due to the large open source committee behind MySQL, it solves a huge number of use cases.
In this particular blog post, we are going to focus on how does one achieve transactional behavior with MySQL and Slick. We will also talk about how these transactions resulted in one of our production outages.
But before going any further into the details, lets first understand what is a database transaction. In the context of databases, a sequence of operations that satisfies some common properties is termed as a transaction. These common set of properties which determine the behavior of these transactions are ACID properties. These properties are intended to guarantee the validity of the underlying data in case of power failure, errors. ACID model talks about the basic principles supported by which one should think before designing database transactions. All of these principles are important for any mission-critical applications.
A transaction, in the context of a database, is a logical unit that is independently executed for data retrieval or updates. In relational databases, database transactions must be atomic, consistent, isolated and durable–summarized as the ACID acronym.
One of the most popular storage engines we use in MySQL is InnoDB, whereas Slick is the modern database query and access library for Scala. Slick exposes the underlying data stored in these databases as scala collections so that data stored onto these databases is seamlessly available. Database Transactions comes with their own set of overhead especially in cases when we have long running queries wrapped in a transaction.
Let’s understand the transaction behavior which we get with slick. Slick offers ways to execute transactions on MySQL.
(for {
ns <- userSessions.filter(_.email.startsWith("mridul@sumologic.com")).result
_ <- DBIO.seq(ns.map(n => userSessions.update(n.copy(n.numSessions + 1))): _*)
} yield ()).transactionally
These transactions are executed with the help of the Auto-Commit feature provided by the InnoDB engine. For the rest of the article, I will be talking about one of the minor outages which happened due to this lack of understanding in this transaction behavior. Whenever any user fires a Query, the query follows this course of action before getting started
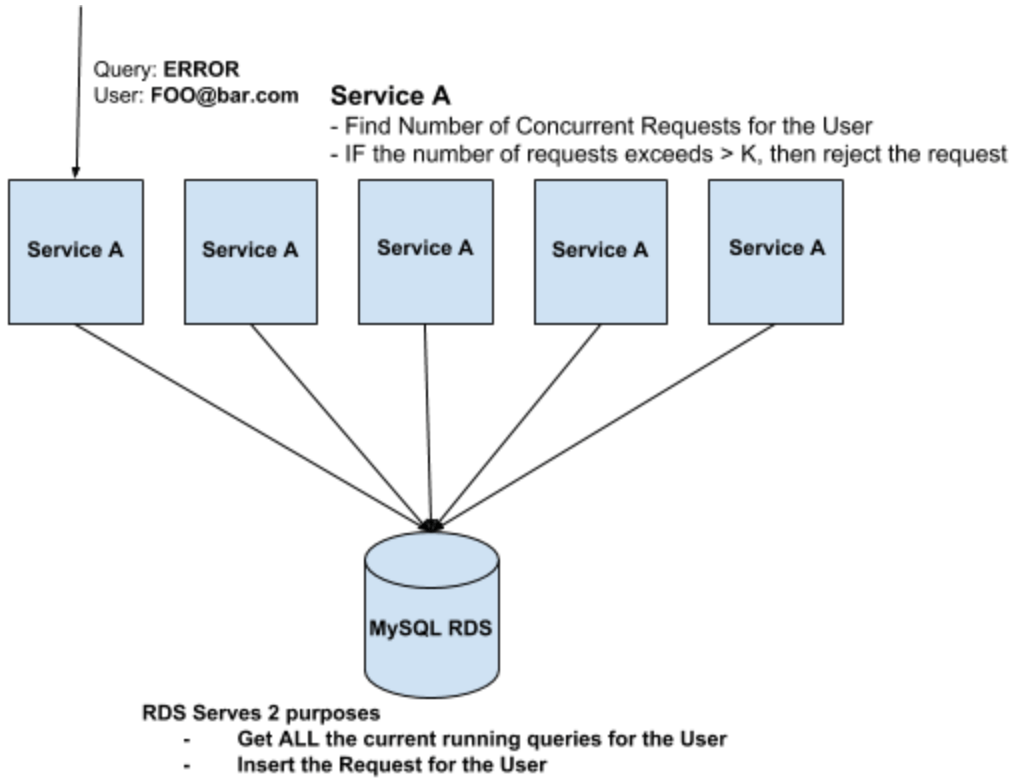
Service A communicating with Amazon RDS Recently we started receiving lots of lock wait timeouts on this service. On debugging further, we saw that from the time we started getting lots of lock wait time timeouts, there was an increase in the average CPU across the cluster. On digging further, whenever we had an instance in the cluster having high CPU, that resulted into higher lock wait timeouts across the cluster. But interestingly the lock wait timeouts were all across the cluster and not isolated on the single instance which suffered from high CPU.
So we knew somehow that high CPU on one of the nodes was somewhat responsible for causing those failures across the cluster. As already told, we were using transactions for every request that came our way.
Now we dig deeper into the code for SLICK to understand how did they implemented transactions. We found out that slick uses the InnoDB feature of auto-commits to execute transactions. In autocommit mode, the transaction is kept open until the transaction is committed from the client side which essentially means that the connection executing the current transaction holds all the locks until the transaction is committed.
In InnoDB, all user activity occurs inside a transaction. If autocommit mode is enabled, each SQL statement forms a single transaction on its own. By default, MySQL starts the session for each new connection with autocommit enabled, so MySQL does a commit after each SQL statement if that statement did not return an error. If a statement returns an error, the commit or rollback behavior depends on the error. SeeSection 14.21.4, “InnoDB Error Handling”.
A session that has autocommit enabled can perform a multiple-statement transaction by starting it with an explicit START TRANSACTION or BEGIN statement and ending it with a COMMIT or ROLLBACK statement. See Section 13.3.1, “START TRANSACTION, COMMIT, and ROLLBACK Syntax”.
If autocommit mode is disabled within a session with SET autocommit = 0, the session always has a transaction open. A COMMIT or ROLLBACK statement ends the current transaction and a new one starts.
Focus on the last statement. This meant that if auto-commit is disabled, then the transaction is open which means all the locks are still with this transaction.
All the locks, in this case, will be released only when we explicitly COMMIT the transaction. So in our case due to high GC / high CPU when we were not able to execute the remaining commands within the transaction meant that we were still holding onto the locks on the table and hence which would mean that other JVMs executing the transaction touching the same table ( which is, in fact, the case ), will too suffer from high latencies.
But we needed to be sure whether it was the case on our production envs. So we went ahead with reproducing the production issue on the local testbed and making sure that locks were still held by the transaction on the node undergoing high GC cycles.
Step 1: We needed some way to know when were the queries in the transactions were actually getting executed by the MySQL server
mysql> SET global general_log = 1; mysql> SET global log_output = 'table'; mysql> SELECT * from mysql.general_log;
So MySQL general logs show the recent queries which were executed by the server.
Step 2: We needed two different transactions to execute at the same time in different JVMs to understand this lock wait timeout.
Transaction 1: val query = (for { ns <- userSessions.filter(_.email.startsWith(name)).length.result _ <- { println(ns) if (ns > n) DBIOAction.seq(userSessions += userSession) else DBIOAction.successful(()) } } yield ()).transactionally db.run(query) Transaction 2: db.run(userSessions.filter(_.id === id).delete)
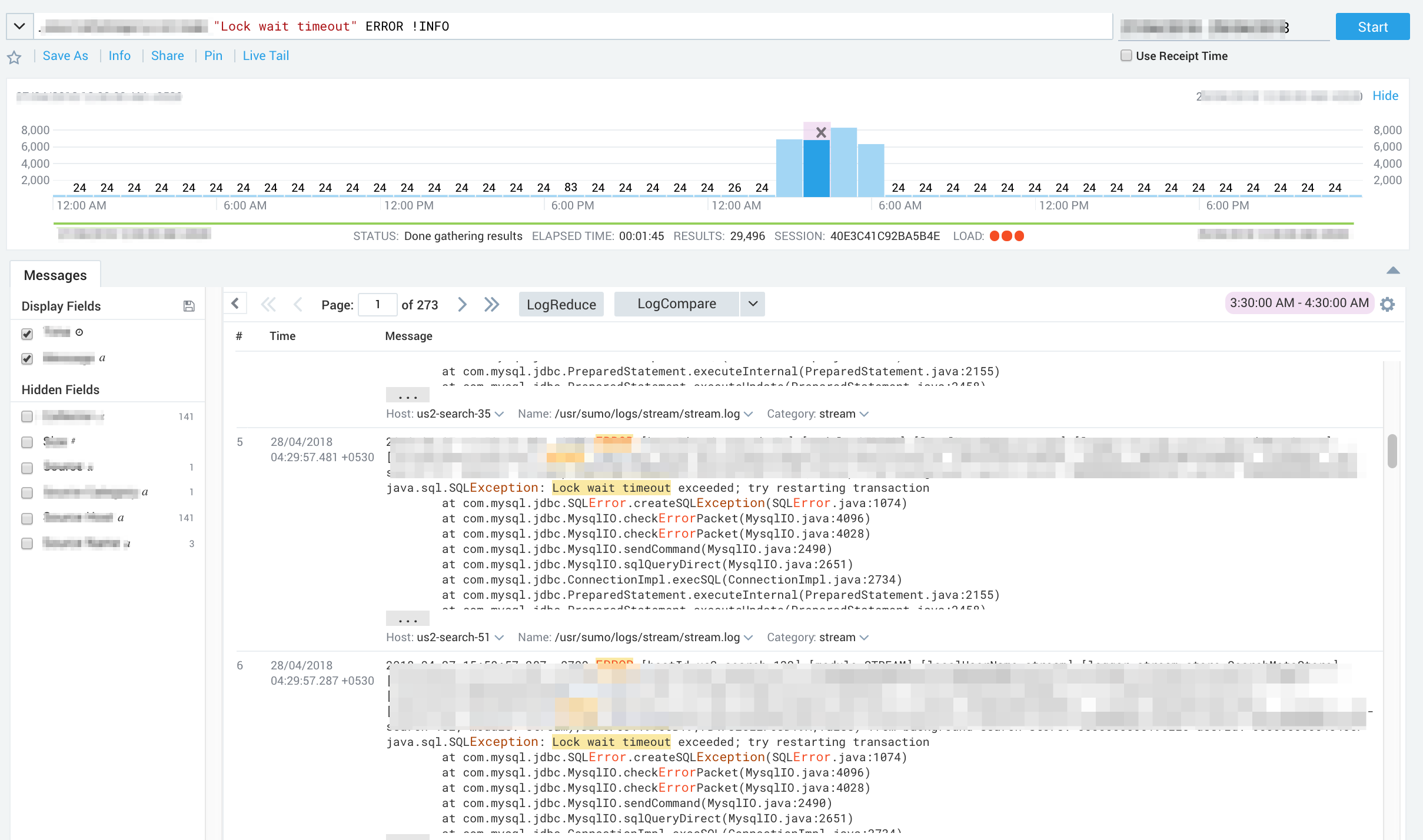
Step 3: Now we need to simulate the long GC pauses or pauses in one of the JVMs to mimic the production env. On mimicking those long pauses, we need to monitor the Mysql.General logs for finding out when did the command reached the MySQL server for asking to be executed.



We can clearly see from the logs how pauses in one JVM causes high latencies across the different JVMs querying on MySQL servers.
Handling Such Scenarios with MySQL
Well, we more than often need to handle this kind of scenario where we need to execute MySQL transactions across the JVMs. So how can we achieve low MySQL latencies for transactions even in cases of pauses in one of the JVMs
- Using Stored Procedures
- With stored procedures, we could easily extract out this throttling logic into a function call and store it as a function on MySQL server
- They can be easily be called out by clients with appropriate arguments and they can be executed all at once on the server side without being afraid of the client side pauses.
- Along with the use of transactions in the procedures, we can ensure that they are executed atomically and results are hence consistent for the entire duration of the transaction.
- Using ExecuteBatch Functionality
- With this, we can create transactions on the client side and execute them atomically on the server side without being afraid of the pauses
- Note: You will need to enable allowMultiQueries=true because this flag allows batching multiple queries together into a single query and hence you will be able to run transactions as a single query.
- Better Indexes on the Table
- With better indexes, we can ensure that while executing SELECT statements with WHERE condition we touch minimal rows and hence ensuring minimal row locks.
- Let’s suppose we don’t have any index on the table, then in that case for any select statement, we need to take a shared row lock on all the rows of the table which will mean that during the execution phase of this transaction all the delete or updates would be blocked. So it’s generally advised to have WHERE condition in SELECT to be on an index.
- Lower Isolation Levels for executing Transactions
- With READ UNCOMMITTED isolation levels, we can always read the rows which still have not been committed.
References
- https://dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html
- http://slick.lightbend.com/
- https://en.wikipedia.org/wiki/ACID_(computer_science)
- https://dev.mysql.com/doc/refman/5.6/en/innodb-autocommit-commit-rollback.html
- https://stackoverflow.com/questions/37955397/what-exactly-does-allowmultiqueries-do
- https://dev.mysql.com/doc/refman/5.5/en/performance-schema.html
